
The Bitter Lesson is Misunderstood
Together, the Bitter Lesson and Scaling Laws reveal that the god of Compute we worship is yoked to an even greater one — the god of Data.
tl;dr: For years, we've been reading the Bitter Lesson backwards. It wasn't about compute — it was about data. Here's the part of Scaling Laws no one talks about:
Translation: Double your GPUs? You need 40% more data or you're just lighting cash on fire. But there's no 2nd Internet (we’ve already eaten the first one). The path forward: data alchemists (high-variance, 300% lottery ticket) or model architects (20-30% steady gains), not chip buyers. Full analysis below.
The Gospel of Scale
For almost a decade, the most important essay in AI has been Rich Sutton’s Bitter Lesson. And for years, I think we’ve profoundly misunderstood it. Talking to dozens of researchers at top labs over the past year, I think this might be the single-most common (and single-most dangerous) fallacy in AI today.
The lesson, as we all learned it, was a beautifully reductionist gospel: stop trying to be clever. Here’s Sutton’s opening sentence:
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.
— Rich Sutton
It taught us that our elegant, hand-crafted features and clever inductive biases were ultimately just temporary crutches. It told us our ingenuity was a bug, not a feature. That the true path to AGI wasn’t more sophisticated algorithms, but "general methods that leverage computation."
And the gospel worked. For years, the only slide that mattered was the one with the loss curve going down and to the right on a log-log plot. We became scaling maximalists, and our faith was rewarded.
I was there. I lived this transition — twice. Before the Bitter Lesson even had a name, I cut my teeth designing and training large-scale multi-sequence HMMs, surfing the paradigm shift from hand-curated models built on thousands of tokens to generalized training on billions of them. And in the last several years, from training statistical models on billions of tokens to training world models1 and early agentic systems on trillions of tokens. We were right to listen.
But we were wrong about what we heard.
The Heresy We All Missed
The Bitter Lesson lays out the spirit of the laws, but the Scaling Laws specify their letter. And the letter, in the form of Chinchilla, revealed that the god of Compute we worship is actually yoked to an even greater one — the god of Data.
Here’s the quarter-sentence from Sutton’s original text we all latched onto:
general methods that leverage computation are ultimately the most effective
For years, we read that and concluded the primary bottleneck was access to computation. We begged, borrowed, and stole our way into multi-billion dollar deals for more TPUs and GPUs. But the scaling laws from DeepMind and OpenAI gave us the fine print on those contracts. They showed that, for a given train-time compute budget (C), there was an optimal size of model (N) and training dataset (D).
But that frames the question we face backwards.
If you invert the logic, something interesting happens. Simplifying for clarity, the usual approximation of the Scaling Laws is that compute scales as the product of model parameters and training tokens (C ~ 6 N⋅D). Chinchilla showed that, for a given compute budget, model size N should scale roughly with data size D (N ~ D).
If you do some basic algebra, you’re left with a starker, more profound relationship:
Simply put, your train-time compute budget scales quadratically with the size of your dataset.2 Conversely, if you double your GPUs, you also have to increase your data by ~40% or you’re just lighting cash on fire.
Let that sink in. This is the real lesson, the one we all missed.
It was never about compute for its own sake.
The heroic feats of computation — whether to radically increase memory, parallelize across thousands of GPUs or invent entirely new silicon just to speed up matmul — were trailing indicators.
Instead, it was always about having a dataset so massive that it enabled a model so massive that together they demanded that level of compute that massive.
The Great Data Bottleneck
And herein lies the problem — we’ve basically ingested the entire Internet, and there is no second Internet. For language models, there’s no obvious way to scale the data.
A study from Epoch AI unpacks things a bit more. In short, while the total sum of human-generated data is vast (~100T to ~1000T tokens), the stock of high-quality text and code suitable for training is 2-3 orders of magnitude smaller. After filtering for quality and duplicates, you’re staring at a pool of ~10T useful pre-training tokens.3
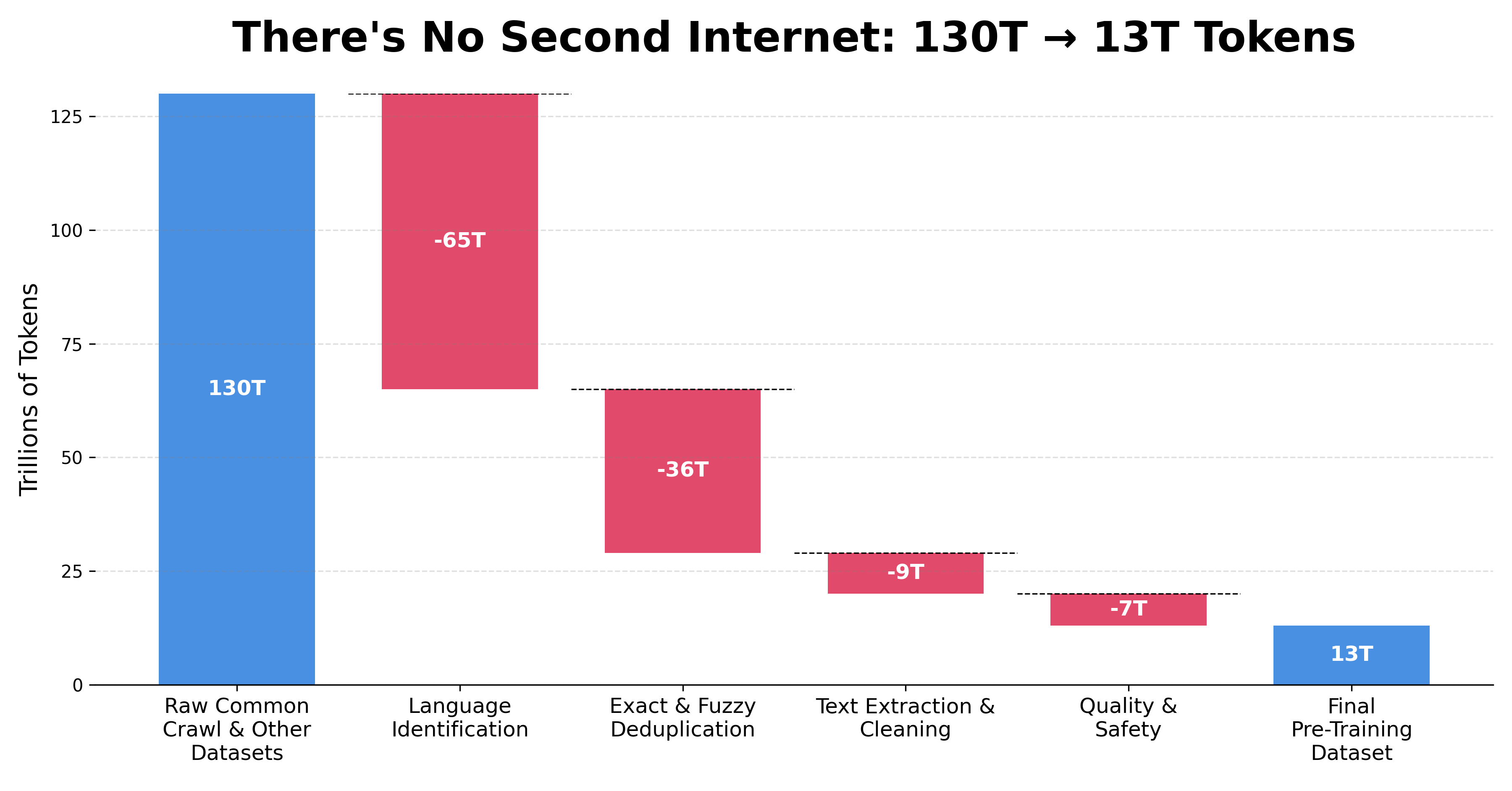
We can use specialized datasets for mid-/post-training, but we’re even reaching the end of that. GitHub is big, but it’s not infinite: we’re strip-mining these resources and the veins of high-quality data for bug-fixes (let alone longer tasks) are running dry. For GPT-6, when you think about METR curves going to 4h and 8h, that maybe you need another O(100Bs) parameters for that, each requiring ~20 tokens per parameter, where do you think that data is coming from?
This is the bottleneck. Without more data, you can’t increase model parameter sizes and without either increasing computation doesn’t make sense. In the wake of GPT5, there’s been a lot of chatter about the Bitter Lesson plateauing. There’s nothing wrong with the Bitter Lesson. At this particular point in time, at this point in data, it’s the central assumption that most people make about The Bitter Lesson is holding us back.
A Longitudinal Prophecy, a Cross-Sectional Fallacy
The Bitter Lesson is a prophecy about the long arc of history, but many misread it as a battle plan for today.
Talking to dozens of AI researchers and leaders over the past year, this misinterpretation is maybe the single-most common (and single-most dangerous) fallacy in AI today.
Fundamentally, Sutton’s lesson is a longitudinal lesson. It correctly observes that, when you zoom out and view progress across decades, simple, general methods that utilize increasing data and compute win out over clever, specialized methods. Over the past decades, it’s been proven true again and again.
But the Bitter Lesson is not a cross-sectional statement. At any fixed point in time, for any fixed amount of data, the Bitter Lesson makes no claim. While incisive, Sutter’s observation is an asymptotic one. And if you’re in charge of an AI team today, asymptopia isn’t useful — you need to survive long enough to capture it, and the markets (and VCs) are fickle, impatient masters.
Think of it like this:
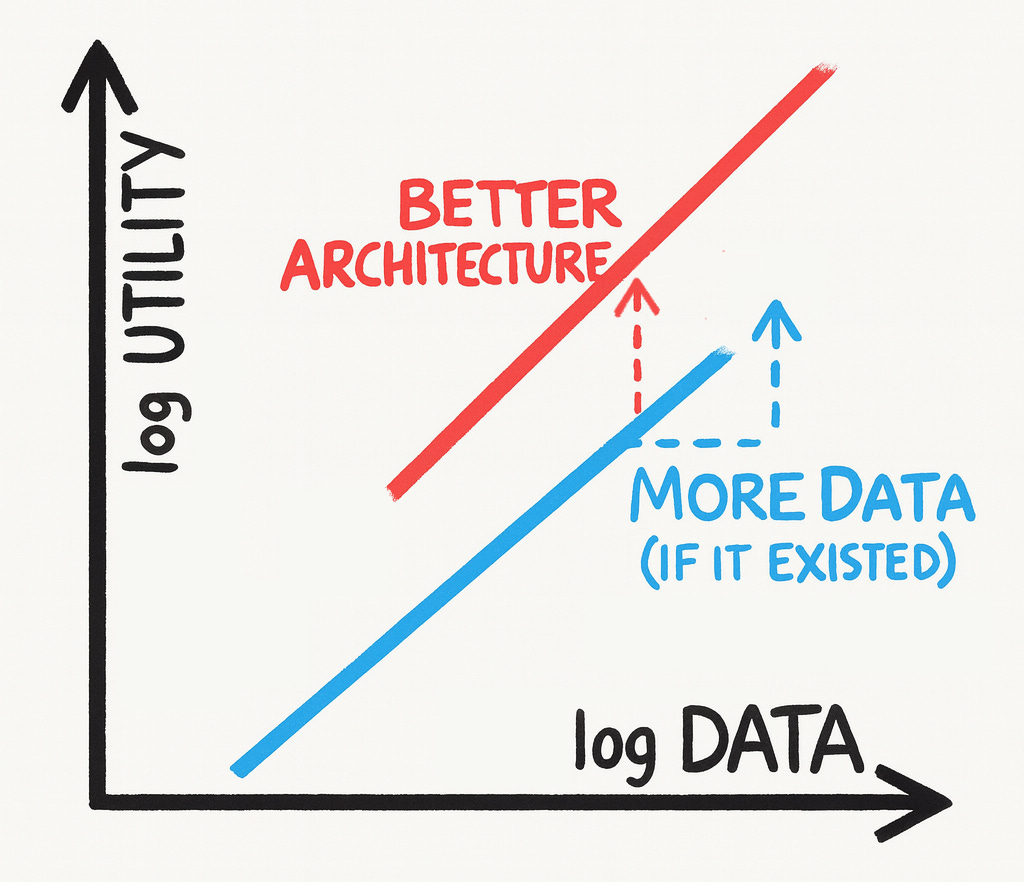
Being grossly reductionist, progress in AI is driven by two fundamental forces:
More Data: As you move (longitudinally) to the right, more (good) data allows you to scale up models, capture novel emergent behaviors and create the magic we’ve all seen over the past few years. In this graph, it looks like a jaunt to the right and up. In a nutshell, the Bitter Lesson.
Better Architecture: But, at a fixed (cross-sectional) point in data, you can also go up by improving the model architecture. Better architectures can enable core capabilities, like Differential Transformer enabling sparser/de-noised attention; enable novel reasoning paradigms, like HRM’s multiple reasoning time-scales; and even multiply usable data, like CLIP basically doubling data by learning from both images and text simultaneously by exploiting spatial proximity.
Translation: If you can’t go to the right (because there’s no more data), there’s still a way up (via architecture). That’s where the Architect comes in.
A Crossroads: The Architect vs. the Alchemist
Combined, the Bitter Lesson and Scaling Laws teach us that more data trumps all else. But with training data for language models now functionally fixed, today’s battle landscape changes. We must either wring more intelligence from every bit (the Architect) or conjure new bits from the void (the Alchemist).
Path #1: An Architectural Renaissance
The Architect's mandate is to discover and embed superior inductive biases into the model’s functional form. The results of this search are redefining the state-of-the-art:
Breaking the O(L²) Bottleneck: Standard Transformers require all-to-all attention, a quadratic bottleneck. The shift to structured State-Space Models (like Mamba) uses linear-time recurrence and selective state compression to handle vastly longer contexts with greater efficiency
Unlocking Deeper Reasoning. Instead of homogenous layers, architectures like Hierarchical Reasoning Model (HRM) from Sapient use conditional computation to route inputs through cheap, shallow paths for simple tasks or expensive, deep paths for complex logic, mimicking System 1/System 2 reasoning.
Discovering New Scaling Laws. And we see it in the most recent ParScale attack on the memory-vs-intelligence bottleneck from Qwen. By running P parallel forward passes of a single model (with shifted learned POVs), it re-uses weights to scale computation instead of memory. It’s the equivalent of scaling the model up by O(N log P) parameters at O(P) memory cost.
This isn’t nostalgia for the hand-tuned features of a bygone era. It’s about structural advantages — symmetries, invariances or causal relationships inherent to the data — that bend the scaling curve in your favor.
Path #2: An Alchemical Breakthrough
The Alchemist’s path is more radical: if the universe of high-quality data is finite, then why don’t we create new universes? Instead of passively consuming data, build engines that generate it, creating feedback loops where models learn from their own experiences and shape data distributions with maximal information gain relative to their current knowledge.
Some of the biggest breakthroughs in recent years have happened here:
Self-Play in Simulated Worlds: This is the canonical example. AlphaGo used Monte Carlo Tree Search (MCTS) to explore the game space of Go, generating novel, superhuman strategies that existed in no human dataset.
Synthesizing Preference and Behavior: The engine of modern alignment. Techniques like RLHF and DPO are fundamentally data-generation processes, creating ranked preference datasets to instill desired behaviors into models.
Agentic Feedback Loop: The frontier. We can achieve credible long reasoning traces by interacting with APIs, databases and code interpreters, but when you combine them with revealed (human) preferences in vertically-integrated tools like Cursor, these long-horizon traces become the new, high-quality dataset to bootstrap next-gen long-reasoning models with real reward signals.
However, this path is a razor's edge. Between model autophagy, specification gaming and the sim-to-real gap, it’s easy to get stuck in dead-ends or get lost in degenerative feedback loops if you don’t have enough ground truth.
Grand Slams, Doubles & Strike-Outs
I pulled ~10 high-profile papers over the last 2 years from each category and then calculated a (quick-and-dirty) Fermi estimate of the % gain in intelligence per unit cost (±% IpC):4
When you look at it, a few things jump out immediately:
First, the Alchemist's Path is a high-variance lottery ticket—when it hits (see DeepSeek R1 and DreamerV3), it completely reshapes the landscape, but it's a game of grand slams or strike-outs.
The Architect's Path is the king of compounding returns; with the exception of the HRM outlier, it’s mostly a steady drumbeat of 20-30% doubles that continually push forward the state-of-the-art.
But the most important insight is this: these two paths aren’t in opposition, Alchemists and Architects are locked in an intertwined dance. Architectural breakthroughs like Mamba are precisely what make running Alchemical bets like DreamerV3 computationally tractable in the first place.
A Leader’s Gambit
So, which do you choose?
This is the wrong question. A research leader’s job isn’t to predict a single future, but to design a research portfolio that can win in different possible futures. The real question is your tolerance for risk.
The Alchemist’s Path offers a high-risk, high-return path. Although a breakthrough in general-purpose RL hasn’t happened yet, it probably will — if you survive long enough to see through the dead ends first. In contrast, the Architect’s Path seems like the “safe” bet. It’s a steady 30% gain, every few quarters. The only problem? It hides the extreme opportunity risk of being made obsolete overnight by a competitor’s 3x breakthrough. As DeepSeek and Qwen showed not so long ago, leapfrogs are real.
Faced with this, I think folks have two primary gambits:
The Incumbent's Gambit (Risk-Off): Allocate most resources (say, 70%) to the Architect's Path. This ensures a steady stream of predictable wins, efficiency gains and product improvements to keep the business running. The Alchemist’s Path is the "lottery ticket"— a smaller, speculative R&D budget (the other 30%) to hedge against being blindsided and start the alchemical dance. Make sure you can fast-follow the rest.
The Challenger's Gambit (Risk-On): Overweight the Alchemist's Path — 70% again, say. This is an aggressive, high-stakes bet to leapfrog incumbents and redefine the market. Here, the 30% allocation to the Architect's Path serves as runway extension — it ensures you’re still shipping something of value regularly and creating enough traction to buy yourself time to land the (eventual) moonshot.
The real risk is not taking a risk. The scaling maximalism of the last decade allowed us to avoid many hard choices — now, we have to think strategically.
Modernizing the Bitter Lesson
If I could update Sutton’s gospel with what we’ve learned from the Scaling Laws, it’d read something like this.
General methods that maximally leverage today’s finite data — subject to tomorrow’s compute limits — are ultimately the most effective, and by a large margin.
— Kushal Chakrabarti
The tragedy is that most teams are still fighting the wrong battle. They’re running the “more GPUs” playbook in a world where the real bottleneck is the data supply chain. If your team is asking for more compute but can’t explain their data roadmap, send them back to the drawing board.
The leaders who win the next era of AI won’t just be scaling models — they’ll be scaling data itself, whether by architecting better use of limited data or alchemizing entirely new unlimited data universes.
The Bitter Lesson wasn’t an excuse to avoid hard choices. It was a warning. With everything we’ve learned in the last 6 years, we should heed an updated warning.
My bottom-line hypothesis: The AI companies that survive 2026 will be the ones who figured out data scarcity in 2025.
This is what kept Opendoor alive when Zillow and Redfin blew up. With all the chatter about Opendoor recently, maybe I’ll write a blog post about that someday.
More mathematically precise derivations and subsequent insights into scaling laws for data-constrained models show that you can push the exponent a bit higher, but the general point still holds.
Adapted from this paper by Epoch AI and other analyses.
What is % gain in intelligence per unit cost, you ask? It’s basically dP&L/dt, but for foundational research. The evals are a dizzying mess of mutually incomparable numbers, so this is my quick-and-dirty way to force-rank different innovations that don’t want to be compared. My Fermi estimates are probably definitely wrong, but they’re right enough to be directionally useful:
Interesting take... I think organizationally buying more compute ends up the more popular choice because of internal incentive structures.
In other words, if you're not OpenAI or another big player with money to burn and you have a fixed budget, buying more compute has a neat little graph associated with it (even if it's made-up) and no one will fault you for following the graph.
On the other hand, investing in clever architecture is a lot riskier because you can't guarantee you will produce the leapfrog insights. But I agree that the ones who are in a position to take such risks definitely should be investing more in them.
Looks like you just coined the Tick-Tock model for ai 🤩